背景
当我们在写Objective-C代码时,会习惯性地把model对象的属性定义为nonatomic。如果该属性是被多线程访问的,那么这样做是有可能crash的。我们可以简单地模拟一下:
|
|
调用上面的methodA方法,程序在运行时会抛出EXC_BAD_ACCESS异常。
如果把属性定义为atomic,我们能避免上面的crash,但仍然存在其他多线程带来的问题。比如竞争条件(race condition)问题,数据一致性问题等等。另外,由于属性是可变的,我们可以在程序的任意地方修改该属性,如果该属性作为某个页面的展示数据,那么我们需要在所有修改的地方发出通知以刷新页面。如果该属性对应的是UITableView的cells,修改该属性而没有通知到UITableView做reloadData的话同样会导致crash。
随着app的不断发展而变得复杂,修改同一个属性的地方会不断增多,所有这些修改和通知会变得很难维护。一旦出现问题,我们也很难找到修改数据的源头,调试这类bug的成本变得很高。
Flux & Redux
对于上面的问题,在js界已经有很成熟的解决方案:Flux和Redux。这两者通过各自的编程规范,来避免上面的数据可变带来的问题。我们以Redux为例,来做具体的分析。下面的分析主要是对Redux官方文档的复述,会有些繁琐,如果你对Redux已经非常熟悉,可跳过该部分。Redux主要有以下几个部分:
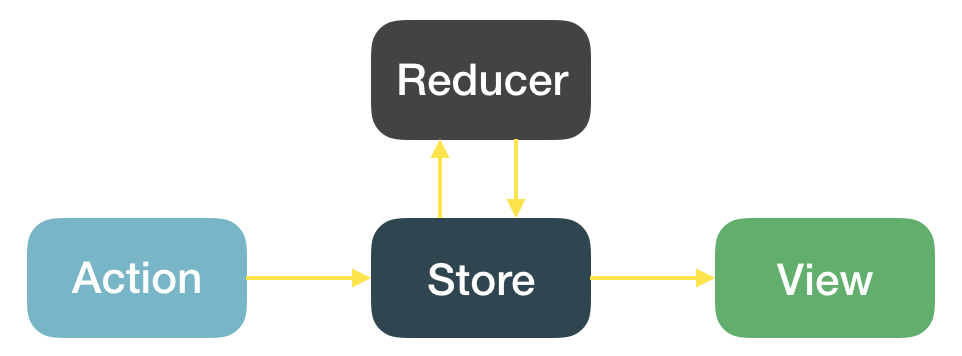
Store
整个app只有一个store,且app的所有数据以dictionary的形式存在该store里。以Redux官网的todo app为例,整个app的数据主要分为两块,todo列表todos和过滤器visibilityFilter:
|
|
Action
对于store里的数据,外部是不能直接修改的。所有数据的修改都必须通过store提供的dispatch接口,传进一个action,在store内部进行。Action是对修改操作的描述:
|
|
用action来描述所有修改操作有很多好处,比如我们可以很方便地记录所有修改以便调试。如果记录了初始状态和所有actions我们也可以很方便地实现回放,撤消(undo)等功能。
Reducer
Store在接收到action后,会通过reducer来修改内部的状态。Reducer只是一些普通的纯函数,输入初始状态和action,输出修改后的状态:
|
|
注意reducer在执行时不会直接修改原数据,而是重新生成整棵状态树,model数据是不可变的。
我们可以看到,在Redux里数据的流向是单向的。数据只能从store流向view,而不能从view流向store。当在view上进行操作需要修改数据时,我们要用action来描述操作,然后把action传进store里,在store内部修改数据。这样,我们就把所有的修改都收拢到了store这一层。同时,我们也只需要在store这一层发出通知来刷新view,所有的通知也被收拢到了一个地方。这样就解决了我们前面提到的修改和通知很难维护的问题。
Objective-C的不适应性
我们可以把Redux这套方案直接应用到Objective-C上,但这样做存在几个问题:
Action的定义
JavaScript是弱类型语言,把action定义为dictionary是很自然的事。但在Objective-C里,如果我们把action定义为NSDictionary,就失去了强类型语言带来的好处。我们也可以为每一个action定义一个相应的类,但这样又会使开发变得很繁琐。通常,客户端app执行一个action操作是比较复杂的,涉及数据库操作和网络请求,大多数时候我们需要再抽出一个方法来执行action。这样同时定义action和定义执行action的方法会使开发变得很重复。
Store的存储
通常客户端app的数据是比较多,而且我们需要在app的多次启动间保存数据。因此,对于大多数客户端app,部分数据是存在磁盘的,我们不可能把所有数据以dictionary的形式存在内存。当数据存在磁盘时,我们也无法用类似reducer的纯函数来修改store的状态。
Reflow解决方案
Reflow参照了Redux的架构和规范,实现了Objective-C语言的单向数据流方案,同时解决了语言的不适应性问题。下面我们来具体的分析一下Reflow:
Store
与Redux类似,在Reflow里我们要求所有的数据都存在store这一层,且所有的修改和通知也收拢到store这一层。但在Reflow里,store是抽象的概念,store里的数据可以存在磁盘,也可以存在内存,也可以是两者的混合。Store这一层通过对外暴露getters接口以拿数据,暴露actions接口以修改数据。随着app的不断发展而变得复杂,我们可以把store划分成多个模块,每个模块都继承于RFStore:
|
|
Action
Action是定义在store上的普通方法,action的方法名都以action开头。Reflow会对所有以action开头的方法做特殊处理:
|
|
在action方法里,我们只需做数据修改的任务,而不用去发通知以刷新UI。并且,在Reflow里,我们建议所有的数据修改都要生成新的model对象并替换,而不是直接修改原model对象的属性。
Subscriptions
继承RFStore后,所有store模块都有subscribe接口。我们可以通过该接口订阅发生在该store模块上的所有action操作:
|
|
每当store模块上的action方法被调用后,该store模块会拼装一个RFAction对象,作为参数调用所有订阅的block。RFAction对象与Redux的action类似,包含了描述一个操作所需的信息:
|
|
我们也可以通过下面的方法订阅所有store模块的所有action,这样我们就可以记录app的所有修改以便调试,也可以很容易地实现回放操作,撤消操作等:
|
|
上面的完整的例子可以参考Github上的Example。
总结
Reflow这个库相对比较小,代码量也很少。对于Reflow来说,更重要的是它的架构设计和规范:
- model对象不可变
- 整个app的数据存于store层
- 更新和通知也收拢于store层
Reflow的设计参考了很多优秀的开源框架和文章,这里把它们列出来以供参考: